SPSS数据分析工具介绍
什么是数据分组?
在面对大量连续型数据时,为了更清晰地观察其分布特征,通常会采用组距分组的方式对数据进行归类整理。具体来说,就是将全部变量值划分为若干个区间,并统计每个区间内的数据频数或频率。这种方法有助于发现数据的集中趋势和离散程度,为后续的图表展示和分析打下基础。
如何确定组数与组距?
在进行数据分组之前,首先需要确定合理的组数与组距。组数的选择应以能够清楚显示数据分布规律为原则,若组数过少则会导致数据过于集中,而组数过多又会使分布过于分散。通常可以参考Sturges公式来估算最佳组数。随后,通过将最大值与最小值之差除以组数,即可得到每组的组距。
SPSS数据分组操作步骤详解
以下将以一个实际案例演示如何在SPSS中完成数据分组操作:
1. 打开SPSS软件并导入所需分析的数据集。
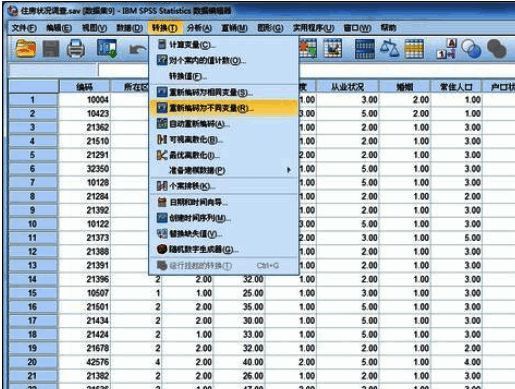
2. 点击菜单栏中的【转换】-【重新编码为不同变量】,调出相关操作界面。
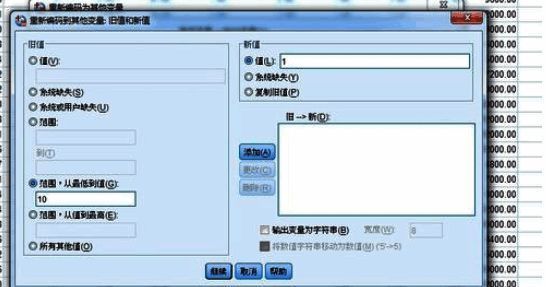
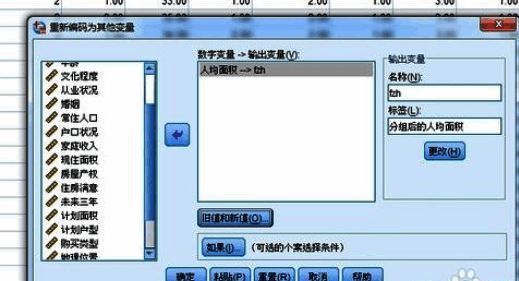
3. 在弹出的窗口中选择“旧值和新值”,进入详细设置界面。
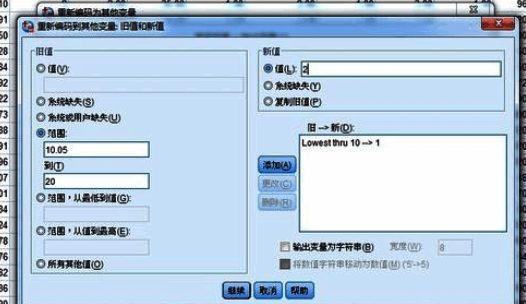
4. 例如,将原始数据中从最小值到10之间的数值归为一组,并设定新组别代号为1;其他范围依此类推,设置完成后点击“添加”按钮保存规则。
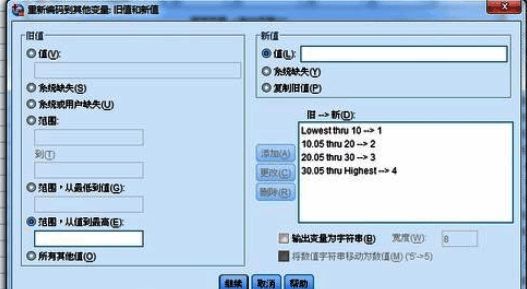
5. 在“输出变量”部分,为新的分组变量命名,如“fzh”,并可添加标签以便识别。
6. 完成所有设置后点击确认,系统将自动生成新的分组变量列。
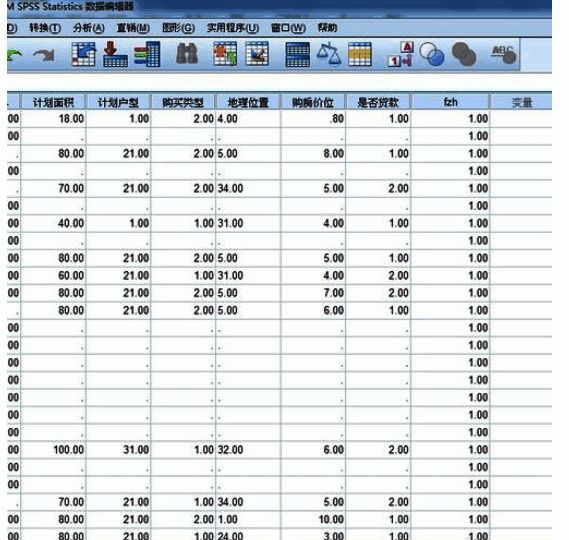
查看分组结果
完成上述操作后,可以在数据视图中看到新增的分组变量列,用于表示各个数据所属的组别。例如,在变量名“fzh”中可以看到分类后的第一组情况,以此类推,所有数据都会根据设定的规则被正确归类。
总结
通过SPSS的“重新编码为不同变量”功能,我们可以轻松实现数据的分组操作。无论是学术研究还是商业分析,这项技能都具有极高的实用价值。掌握好这些基本操作,将有助于提升数据分析效率,挖掘数据背后隐藏的信息。